Project AWS
Going to test out AWS EKS compared to Google's GKS by deploying a cluster and blog using Terraform and Helm charts

In this blog I'll go through some of the steps I take when I create a new project. Thinking of the architecture, IaaC, security, and service deployment.
Infrastructure as code has become the new norm. Learning one language to rule all the clouds. The only difference is the resources being used and the unique switches and knobs that belong to the individual providers. If you are going to succeed, getting chops in TF will be extremely helpful. I will be emulating standing up a new cloud using AWS, Terraform, and Helm.
The Project
Before you start building you need to have an idea of what you are shooting for. In my case, I am setting up another blog just like this one using the same rollout pattern but to AWS instead of GCP. It's been 6 years since I've deployed workloads to AWS so I want to catch up on some of the new patterns they've made available.
Goals: Create comparable setup
- Cloud Setup on AWS
- Init - Remote State and Encryption
- Network - VPC and Subnet
- Service - Could be a team, department, or isolate service
- Helm deployment - blog, db, ingress, and cert manager
We aren't going to worry about the deployment tools because we aren't maintaining this long term.
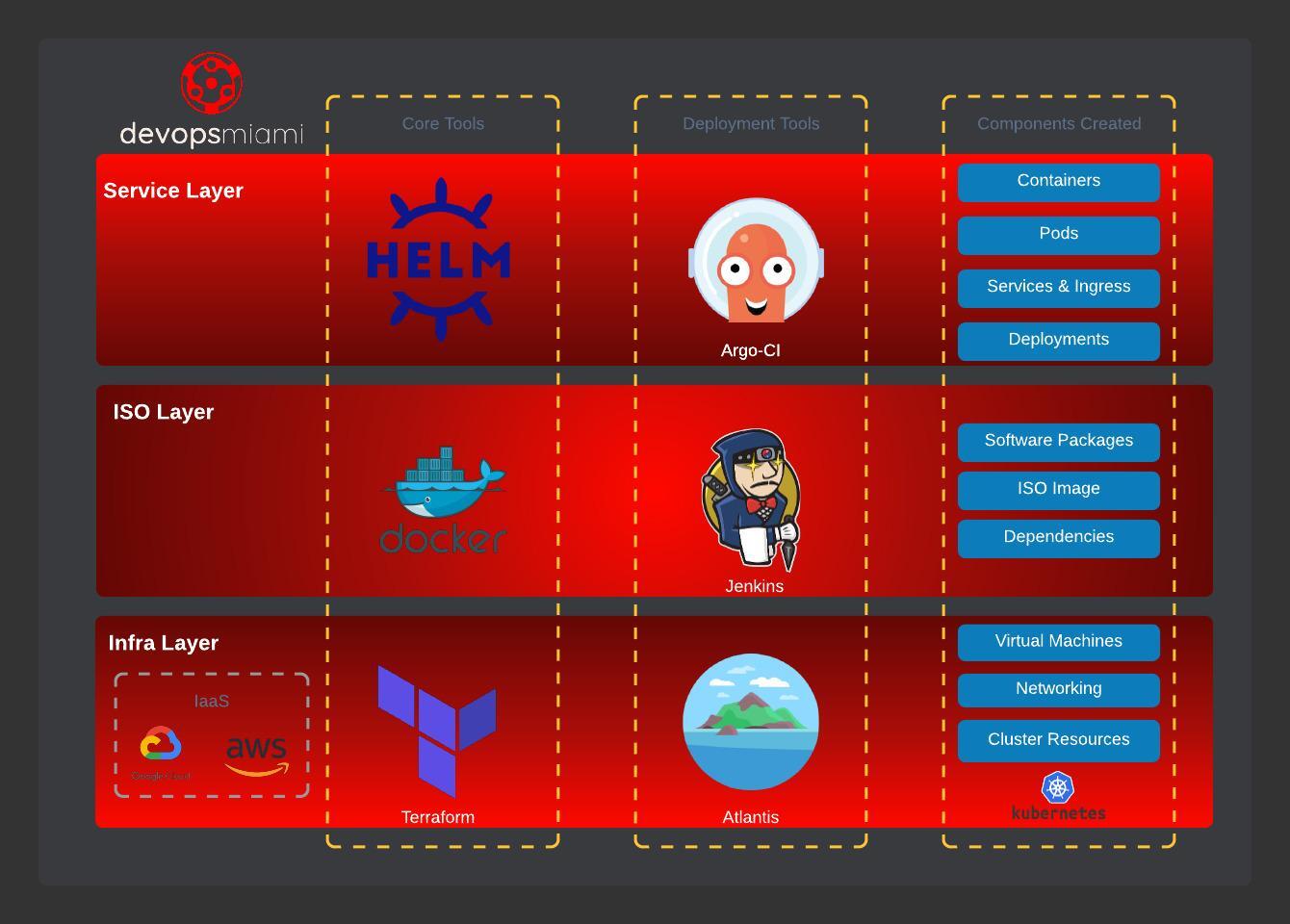
Current Arch
The current arch I use breaks things down into three main layers - infra, iso, and service. The Infra Layer which hosts the Terraform for provisioning cloud components that provide resources for our services to use. In the chart below you can notice the items provisioned on this layer - cluster, networking, and iam policies. The next layer up bundles service dependencies together. This usually happens during CI/CD processes ran in CircleCI, Jenkins, or native offerings like CloudBuild. The final layer is the Service Layer which is responsible for the service deployment. I use Helm and am still working out declarative setups with ArgoCD (really want to get to ArgoRollouts for bluegreen+weighted deployments). So if this chart isn't lying to us, it should pretty straight forward to lift and shift my arch from GCP to AWS.
Take Aways:
- Infra Layer - Terraform - networkings, K8s, IAM. (This is how we setup our infra)
- ISO Layer - Docker/CICD - building and packaging the software that will run on our service layer
- Service Layer - Helm - deploying our software easily to Kubernetes clusters (scaling, pvcs, cert config, service config)
The progress
I am currently working on this process and pattern is holding true I can rewrite my entire bottom layer and keep my middle and top layer almost the same. So far I've gone through the following:
- Day 1 - Setup the AWS org, SSO, user, init folder and remote backend
- Day 2 - Configure SOPs with Terraform tfvars for env/secrets, forloops, network
- Day 3 - Setup my first EKS cluster with basic IAM
- Day 4 - Dive into securing EKS + logging setup
Learnings:
- It's about the same jazz
- This new setup is so much nicer than modules
- Hooking up the authentication api for k8 is next
Architecture Design
With most projects I like to build them similar to environments I deal with at work. Scaling happens at a service, infrastructure, and departmental level. With that said requirements should always drive the arch decisions. In our case lets list some of those out.
- Cost effective (out of my pocket)
- Same as the current blog's stack (k8, helm, docker)
- Experiment with cross department ownership (network, iam, devops, obs, security)
- Experiment with apply top down iam policies across accounts
- System must allow for easy provisioning (built and destroyed after every session)
So what does this translate to? We want to experiment with the idea of there being an entire organization at work with many parts moving in the machine. Splitting an org into different accounts allows for the billing and accounting to happen with ease. IAM policies can or cannot be applied depending on the nature of the department. Communication across projects between services also present their own challenges as well.
Working at CK, I did a deployment and found myself having to split my TF into the section that I owned and the section that network team owned. This is a bit cumbersome because when it comes time to troubleshoot things we only own half of the story. I keep this complexity around so it feels less painfull at work. In most cases test/qa/stage helps but some services cannot be emulated like CDN rules.
The issue with stuff like this is boiling the ocean - too much to do in too little time. So, we will KISS and keep it simple stupid. Some of the bare minimal and we can expand from there keeping our focus on security.
Scope
In this article we will discuss setting up the following:
- Init - Backend and Secrets (mozilla SOPs)
- Network - VPC and Subnets
- Service - EKS cluster
- EKS Access Policies / API Auth for EKS
*** WIP ***
Don't think anyone will see this yet except Dom. If you are someone other than Dom, here is the github link.
 devops-miami
devops-miamiInit
This folder contains all the configs for setting up your kms key, dynamodb, and s3 bucket to maintain your remote state and encrypt your secrets. After cloning the repo cd into the init folder and run tf apply. I'm assuming you already set up all you things like iam, accounts, and tokens.